Completeness (statistics)
In statistics, completeness is a property of a statistic in relation to a model for a set of observed data. In essence, it is a condition which ensures that the parameters of the probability distribution representing the model can all be estimated on the basis of the statistic: it ensures that the distributions corresponding to different values of the parameters are distinct.
It is closely related to the idea of identifiability, but in statistical theory it is often found as a condition imposed on a sufficient statistic from which certain optimality results are derived.
Contents |
Definition
Consider a random variable X whose probability distribution belongs to a parametric family of probability distributions Pθ parametrized by θ.
Formally, a statistic s is a measurable function of X; thus, a statistic s is evaluated on a random variable X, taking the value s(X), which is itself a random variable. A given realization of the random variable X(ω) is a data-point (datum), on which the statistic s takes the value s(X(ω)).
The statistic s is said to be complete for the distribution of X if for every measurable function g the following implication holds:
- E(g(s(X))) = 0 for all θ implies that Pθ(g(s(X)) = 0) = 1 for all θ.
The statistic s is said to be boundedly complete if the implication holds for all bounded functions g.
Example 1: Bernoulli model
The Bernoulli model admits a complete statistic.[1] Let X be a random sample of size n such that each Xi has the same Bernoulli distribution with parameter θ. Let T be the number of 1's observed in the sample. T is a statistic of X which has a Binomial distribution with parameters (n,θ). If the parameter space for θ is [0,1], then T is a complete statistic. To see this, note that
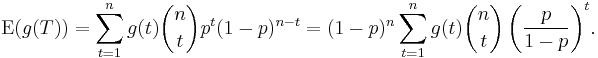
Observe also that neither p nor 1 − p can be 0. Hence 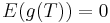 if and only if:
if and only if:
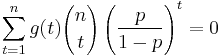
One denoting p/(1 − p) by r one gets:
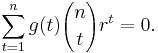
First, observe that the range of r is all reals except for 0. Also, E(g(T)) is a polynomial in r and, therefore, can only be identical to 0 if all coefficients are 0, that is, g(t) = 0 for all t.
It is important to notice that the result that all coefficients must be 0 was obtained because of the range of r. Had the parameter space been finite and with a number of elements smaller than n, it might be possible to solve the linear equations in g(t) obtained by substituting the values of r and get solutions different from 0. For example, if n = 1 and the parametric space is {0.5}, a single observation, T is not complete. Observe that, with the definition:
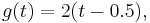
then, E(g(T)) = 0 although g(t) is not 0 for t = 0 nor for t = 1.
Example 2: Sum of normals
This example will show that, in a sample of size 2 from a normal distribution with known variance, the statistic X1+X2 is complete and sufficient. Suppose (X1, X2) are independent, identically distributed random variables, normally distributed with expectation θ and variance 1. The sum
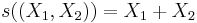
is a complete statistic for θ.
To show this, it is sufficient to demonstrate that there is no non-zero function 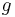 such that the expectation of
such that the expectation of
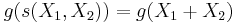
remains zero regardless of the value of θ.
That fact may be seen as follows. The probability distribution of X1 + X2 is normal with expectation 2θ and variance 2. Its probability density function in  is therefore proportional to
is therefore proportional to
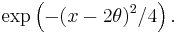
The expectation of g above would therefore be a constant times
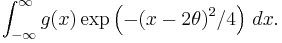
A bit of algebra reduces this to
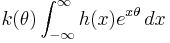
where k(θ) is nowhere zero and
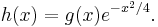
As a function of θ this is a two-sided Laplace transform of h(X), and cannot be identically zero unless h(x) is zero almost everywhere. The exponential is not zero, so this can only happen if g(x) is zero almost everywhere.
Relation to sufficient statistics
For some parametric families, a complete sufficient statistic does not exist. Also, a minimal sufficient statistic need not exist. (A case in which there is no minimal sufficient statistic was shown by Bahadur in 1957. ) Under mild conditions, a minimal sufficient statistic does always exist. In particular, these conditions always hold if the random variables (associated with Pθ ) are all discrete or are all continuous.
Importance of completeness
The notion of completeness has many applications in statistics, particularly in the following two theorems of mathematical statistics.
Lehmann–Scheffé theorem
Completeness occurs in the Lehmann–Scheffé theorem, which states that if a statistic that is unbiased, complete and sufficient for some parameter θ, then it is the best mean-unbiased estimator for θ. In other words, this statistic has a smaller expected loss for any convex loss function; in many practice applications with the squared loss-function, it has a smaller mean squared error among any estimators with the same expected value.
See also minimum-variance unbiased estimator.
Basu's theorem
Bounded completeness occurs in Basu's theorem,[2] which states that a statistic which is both boundedly complete and sufficient is independent of any ancillary statistic.
Bahadur's theorem
Bounded completeness also occurs in Bahadur's theorem. If a statistic is sufficient and boundedly complete, then it is minimal sufficient.
Notes
- ^ Casella, G. and Berger, R. L. (2001). Statistical Inference. (pp. 285-286). Duxbury Press.
- ^ Casella, G. and Berger, R. L. (2001). Statistical Inference. (pp. 287). Duxbury Press.
References
- Basu, D. (1988). J. K. Ghosh. ed. Statistical information and likelihood : A collection of critical essays by Dr. D. Basu. Lecture Notes in Statistics. 45. Springer. ISBN 0-387-96751-6. MR953081.
- Bickel, Peter J.; Doksum, Kjell A. (2001). Mathematical statistics, Volume 1: Basic and selected topics (Second (updated printing 2007) of the Holden-Day 1976 ed.). Pearson Prentice–Hall. ISBN 013850363X. MR443141.
- E. L., Lehmann; Romano, Joseph P. (2005). Testing statistical hypotheses. Springer Texts in Statistics (Third ed.). New York: Springer. pp. xiv+784. ISBN 0-387-98864-5. MR2135927. http://www.springerlink.com/content/978-0-387-98864-1#section=545952&page=1.
- Lehmann, E.L.; Scheffé, H. (1950). "Completeness, similar regions, and unbiased estimation. I.". Sankhyā: the Indian Journal of Statistics 10 (4): 305–340. JSTOR 25048038. MR39201.
- Lehmann, E.L.; Scheffé, H. (1955). "Completeness, similar regions, and unbiased estimation. II". Sankhyā: the Indian Journal of Statistics 15 (3): 219–236. JSTOR 25048243. MR72410.